






Access to data
Access to data means that you determine who you make your data available for, how you provide access, and under which conditions.
Access to data
Conducting research is often a team effort. Even before collecting the data, it is important to consider who will get access to the data, under which conditions and what permissions they will have.
If your data are personal, confidential, or contain copyrighted material, you have both a legal and ethical obligation to make sure that only the research project members can access the data during data collection and processing.
Plan for access
As you create and collect data it is important to have a plan for the access to your data in a data management plan. In the plan, reflect on the following questions:
- Who are the data available for and under which conditions?
- How are the data backed up?
- How is the above documented?
- Intellectual Property Rights (IPR) agreements may restrict access to data sets both during the collection and after finalising the project.
Always consider how you store and backup your data – both during data collection and processing. Agree with your collaborators on standard procedures and document or even better: log all data access during the active research phase.
Learn more
For your project there may be specific data management demands that apply. To learn more, take our course on data management plans
What about sensitive data?
Sensitive data can be FAIR without being open. The FAIRness is made by a clear description on how access to the data can be granted e.g. for research purposes.
A lot of research is based on sensitive personal data, data protected by IPR (Intellectual Property Rights) agreements or confidential data. This means that access to the data must be managed and restricted.
Example 1
What other options do you have for providing access to sensitive personal data?
While you work, access to sensitive data is restricted to the researchers conducting the project.
To share sensitive data with others, you can anonymise (change to impersonal ID's) or de-identify (remove ID's) them - but there are many problems with this approach:
The first problem...
is that anonymisation is not trivial and may even be impossible. For instance, if you have a CT scan of the head of a patient others might be able to make a surface reconstruction that in some cases could break the intended anonymisation if the patient has some specific anomalies.
If you can’t anonymise, you can’t directly give access.

The second problem...
is that it is not possible to add new data to anonymised patient information. So, if, 5 years later, you observe that the patient is still alive, you cannot just add that piece of information.
This limits the reusability of the data.
The classical way...
to work with data from different institutes is to pool them on a central server, which hosts the analysis tools, creating a data lake. You collect the data, you perform your analysis and then you effectively throw them away.
The data are often not reusable and therefore not perfectly FAIR.
Example 2
Distributed learning
Within Carsten Brink’s research area, researchers from all over the world work together. To predict what outcome a treatment for their patients will have, they develop a model. They can base this model on the patient data at their own hospital, but in some cases, the model will require more data than their own hospital can provide. In this case, they can send their model from institute to institute, collecting results along the way. This is called Distributed Learning.
Now they can analyse a large pool of results without moving sensitive data.
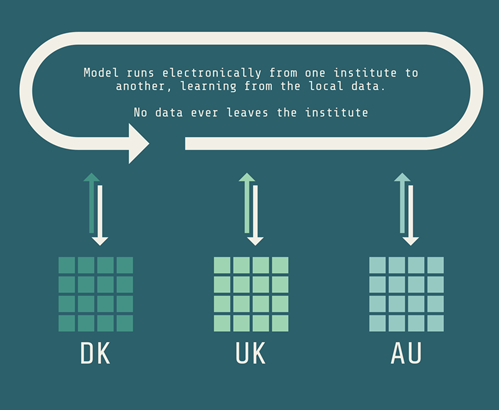
Depending on the size of the project, distributed learning can be a FAIR practice to handle sensitive personal data responsibly, but it does require a substantial overhead of mapping data to a standard format.
Learn more about distributed learning here.
Publish or preserve
In the final phase of your research project, you stipulate who can use your data and how others can gain access to it. You need to consider if and how and where you will publish or preserve your data.
The specifics on who can access the data and how should be included, not only in your publications, but also in your published metadata.
From a FAIR perspective, access to data does not mean making data open. Instead, you have to specify who can access the data under what conditions or whom to ask for permission to access the data.
If the data are personal or otherwise sensitive, they should only be preserved, if there is a legal basis; and protocols for access have to be carefully considered.
Sensitive data?
In Denmark, only the National Archives can store and preserve sensitive data long term without consent. To guarantee long term access to your data, contact the national archives and hand your data in for preservation.
Example 3
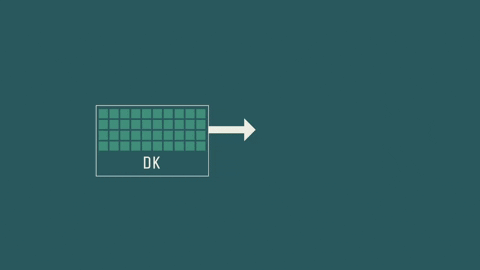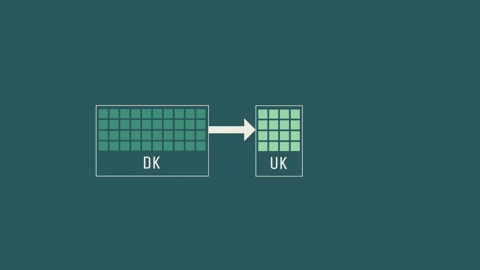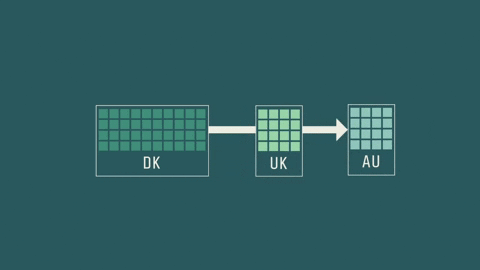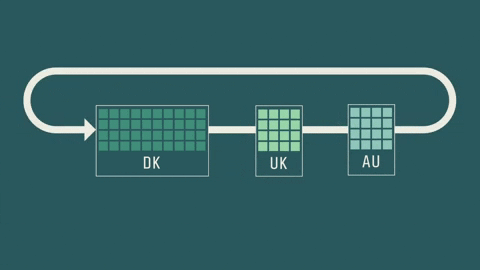
In Carsten Brink’s case, at the end of the research project the data will stay at his institute so that new data can be added all the time.
Other researchers can apply for access, and, if approved, they can send a model to analyse the local data. They will never get physical access to the raw data.
Example 4
In Nikola Vasiljević’s case the data are not sensitive and, due to progressivism from Vestas Wind systems A/S, the data are not even confidential to protect commercial interests.
Where else can you preserve your research data?
Many institutions and public organisations have established data repositories, where scientists can upload and share their data. Projects funded by the European Union are expected to make generated data or their metadata available to the public - for example through data repositories.
To search for a suitable repository for your research data you can visit re3data.org, which is a global registry of research data repositories from different academic disciplines, FAIRsharing, which allows you to discover databases grouped by domain, species or organization, or check the links page to find more resources on data repositories.