





Metadata
Metadata are data about data. Research data need metadata to become findable, accessible, interoperable and reusable - by humans and machines.
What are metadata?
Metadata are data about data. They play an important role in making your data FAIR. Metadata have to be added continuously to your research data, not just at the beginning or at the end of a project. Metadata can be added manually or automatically, and preferably according to a disciplinary standard. From a FAIR perspective, metadata are more important than your data, because metadata would always be openly available and they link research data and publications in the Internet of FAIR Data and Services. The distinction between data and metadata is not ontological, but it is grounded in use. What is “data” and what is “metadata” is thereby a matter of perspective: Some researchers’ metadata can be other researchers’ data.
While data documentation is meant to be read and understood by humans, metadata (which are sometimes a part of the documentation) are primarily meant to be processed by machines.
Three types of metadata
We distinguish between three main types of metadata:
- Administrative metadata are data about a project or resource that are relevant for managing it; for example, project/ resource owner, principal investigator, project collaborators, funder, project period, etc. They are usually assigned to the data, before you collect or create them.
- Descriptive or citation metadata are data about a dataset or resource that allow people to discover and identify it; for example, authors, title, abstract, keywords, persistent identifier, related publications, etc.
- Structural metadata are data about how a dataset or resource came about, but also how it is internally structured. Structural metadata describe, for example, the unit of analysis, collection method, sampling procedure, sample size, categories, variables, etc. Structural metadata have to be gathered by the researchers according to best practice in their research community and will be published together with the data. Descriptive and structural metadata should be added continuously throughout the project.
Let's have a look at some metadata examples from our case projects.
NB!
Since your data may change while you conduct your research, you should make sure that your metadata change accordingly.
Example 1: ISSP
Example 2: Danish Parliament Corpus
The Language Technology Group has published their dataset, the Danish Parliament Corpus (2009-2017), in CLARIN-DK, a repository for language-based, textual data. CLARIN-DK is the Danish part of CLARIN ERIC, a European research infrastructure for the Humanities. During the data submission process, CLARIN-DK guides the user to systematically upload relevant administrative, descriptive, and structural metadata together with the dataset.
Here you can see screenshots of the data submission pages of CLARIN-DK, where the three types of metadata are marked in different colours (light green = administrative metadata; yellow = descriptive metadata; dark green = structural metadata).

Example 3: Wind Energy
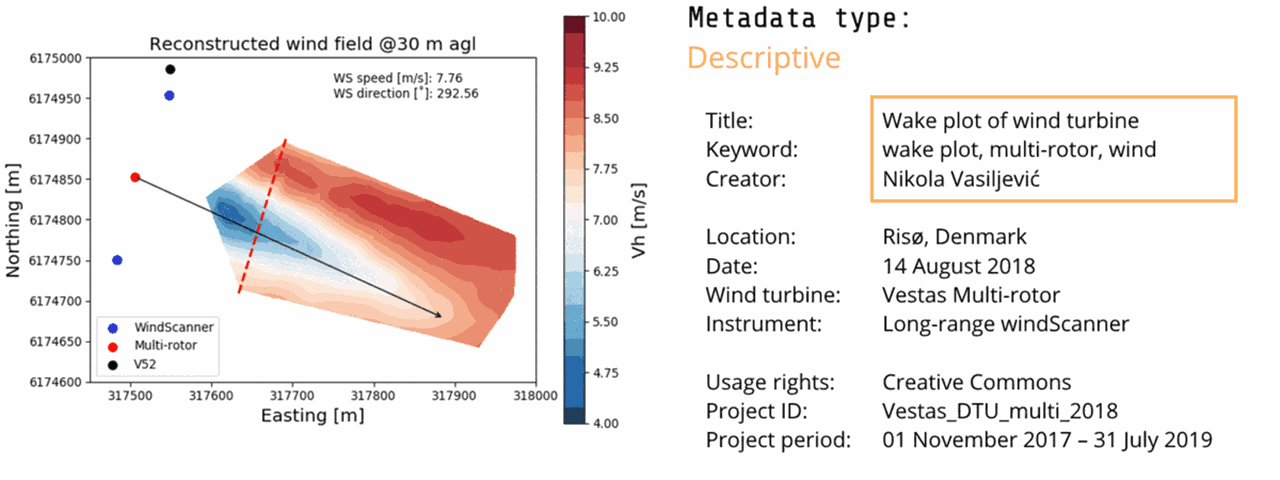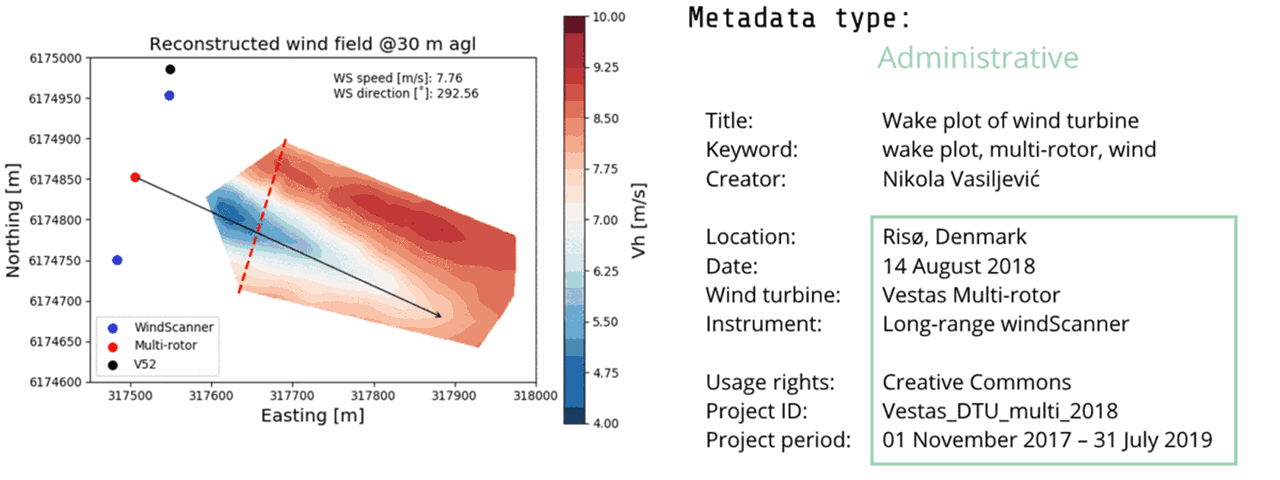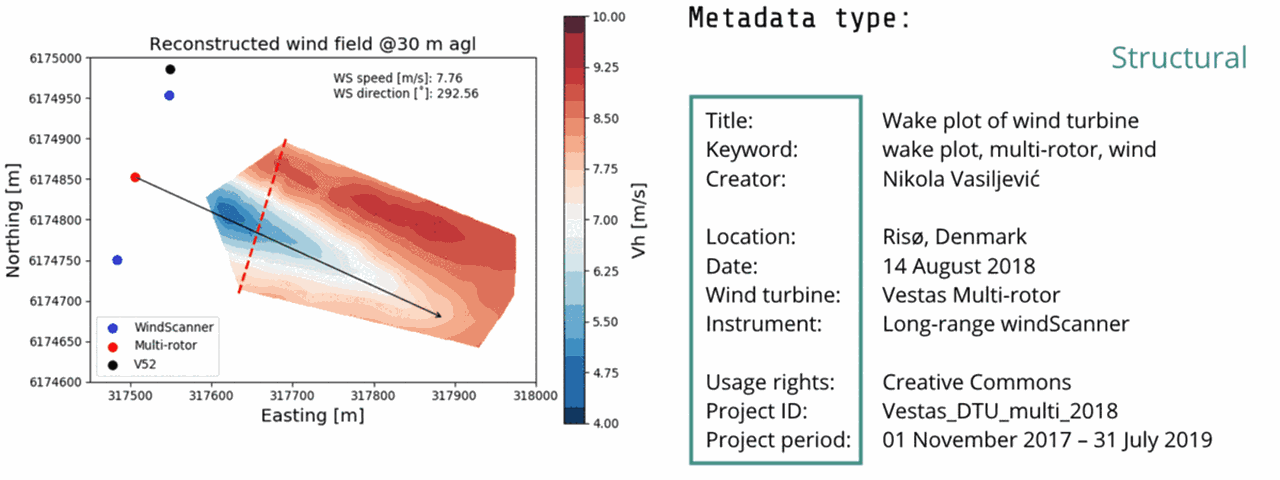
Here you can see a single plot from the Multi-lidar observations of the Vestas multi-rotor turbine wake project with its attached metadata.
The descriptive metadata (yellow) describe the plot for discovery and identification purposes and include elements such as title, abstract, author, and keywords.
The administrative metadata (light green) provide information to help manage the digital object, such as: information about when and how it was created, file type, licence and access rights. Finally, the data are provided with a project ID that informs about the relation to a project.
The structural metadata (dark green) specify the internal structure of the digital object, in this example: the plot variable names and units that define the relationship between the variables in the plot.
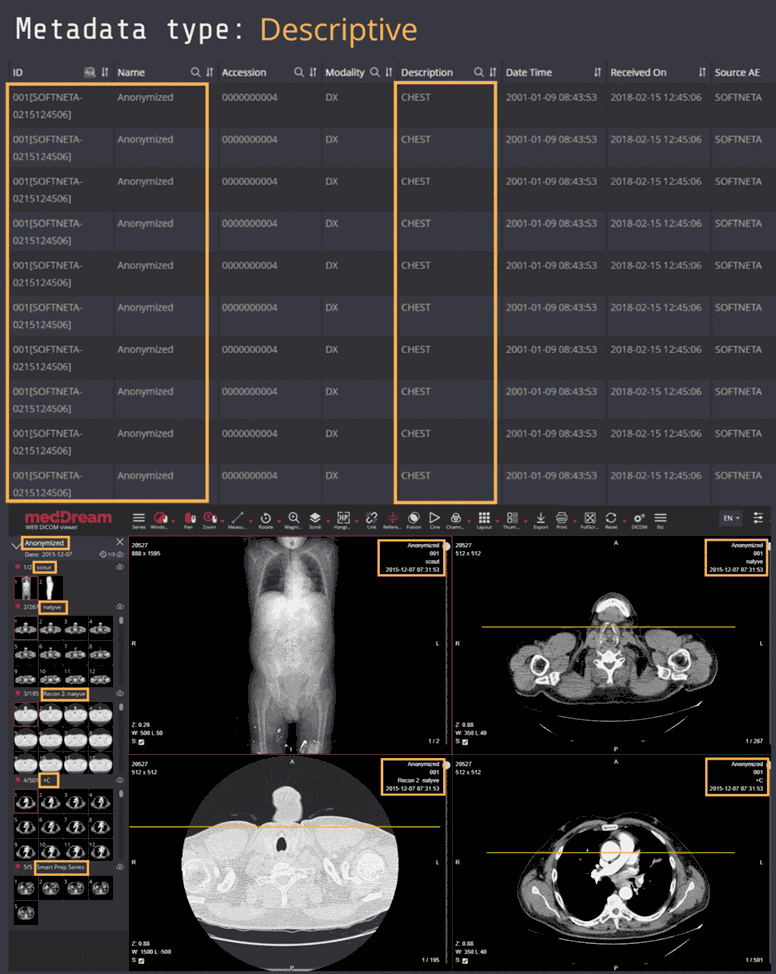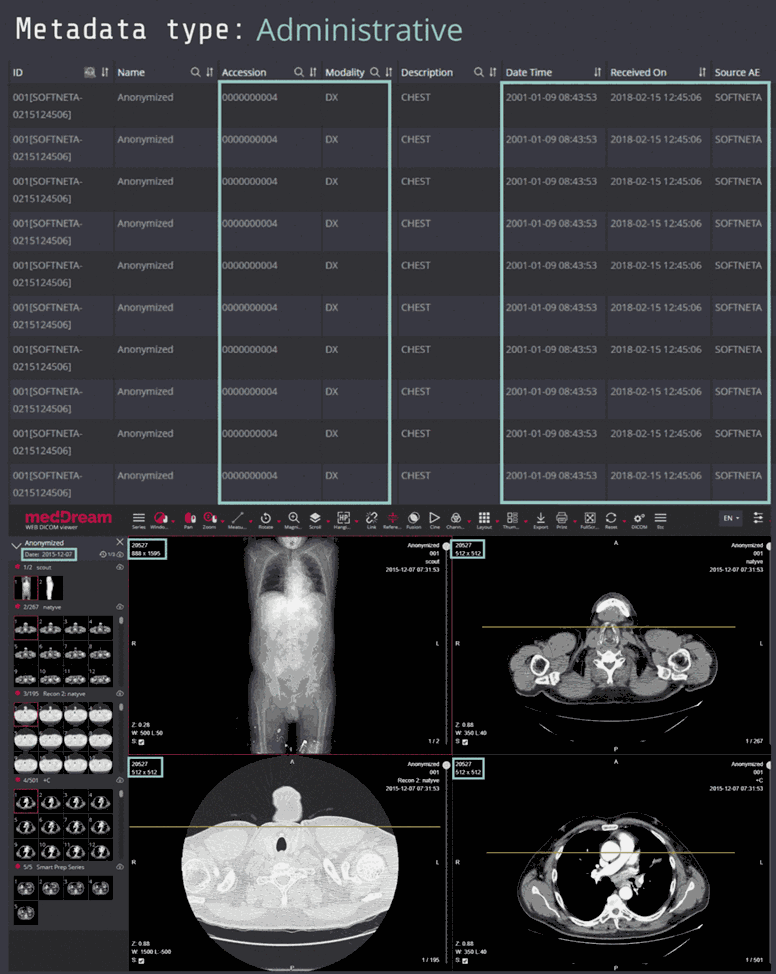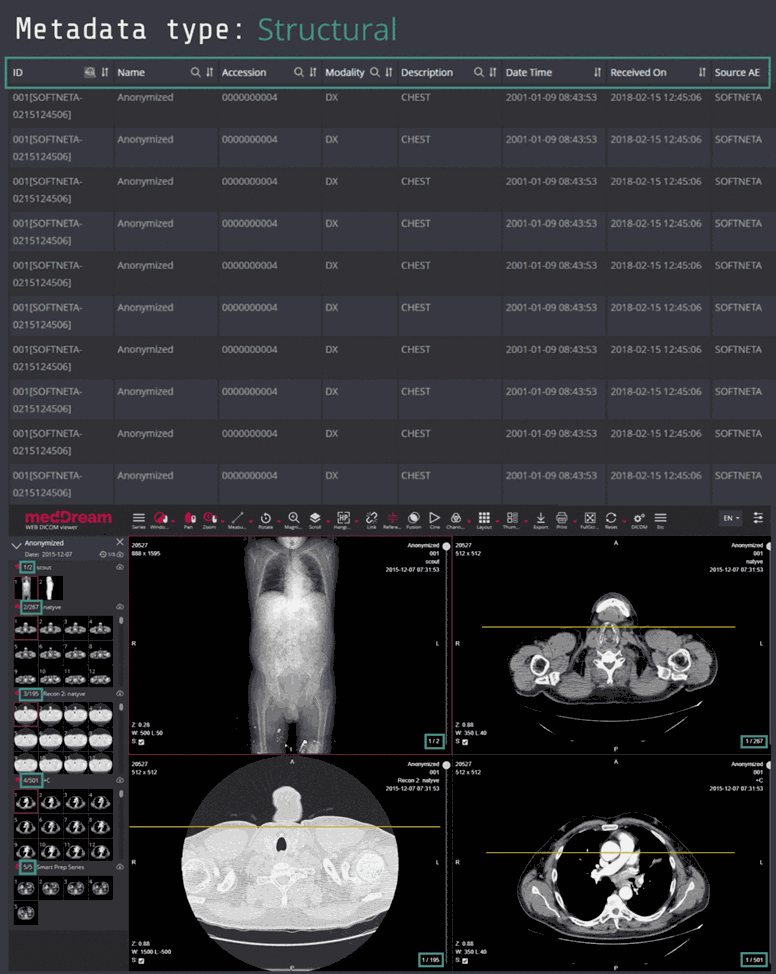
Example 4: Radiography
Here you can see screenshots of a database of radiography images, where the three types of metadata are marked in different colours (light green = administrative metadata; yellow = descriptive metadata; dark green = structural metadata).
You can see that the three types of metadata apply not only to the database, but also to individual images and sets of data.
Click on the screenshot to enlarge it.
Metadata standards and ontologies
The quality of your metadata has a huge impact on the reusability of your research data. It is best practice to use a discipline-specific metadata standard and/or an ontology commonly used in your field to describe your data. Some data repositories can help you in choosing the appropriate metadata standard for your data.
Have a look at the links page to get started.
What is a metadata standard?
A metadata standard is a subject-specific guide to your metadata. Metadata elements are grouped into sets designed for a specific purpose and given a standard name and definition. Rules on what content must be included, what syntax must be used, or a controlled vocabulary can also be included in a metadata standard.
Important, internationally recognized metadata standards for research data are for example the Dublin Core Metadata Standard for bibliographic information, the Data Documentation Initiative (DDI) for survey and observational data (Social Sciences), and the Text Encoding Initiative (TEI) for textual data (Digital Humanities).
Learn more
Many research disciplines have developed metadata standards for research data. Read more about disciplinary metadata standards here.
If you want to check if there is a metadata standard for your research discipline go to FAIRsharing
Using a metadata standard is vital to Ditte Shamshiri-Petersen's work, as her research makes up part of the International Social Survey Programme (ISSP).
All ISSP metadata are published in the technical reports together with the data sets on the ISSP website. The metadata are structured according to the Data Documentation Initiative, short DDI. The DDI provides a very detailed framework for structuring and describing survey data and other types of observational data in the Social Sciences.
What is an ontology?
An ontology (or controlled vocabulary) provides a standard definition of key concepts in a subject area with focus on how those concepts are related to one another. It can be used to define the structure of your data.
An ontology is considered to be a subset of a taxonomy, which is a hierarchically structured conceptual representation of a subject area. Ontologies and taxonomies are closely related, but distinct concepts.
Learn more
For more information about the differences between an ontology and a taxonomy have a look at the Dataversity webpage.
What can you do if there is no standard in your field?
Metadata standards often start as schemas developed by a particular research group or community to enable the best possible description of their data.
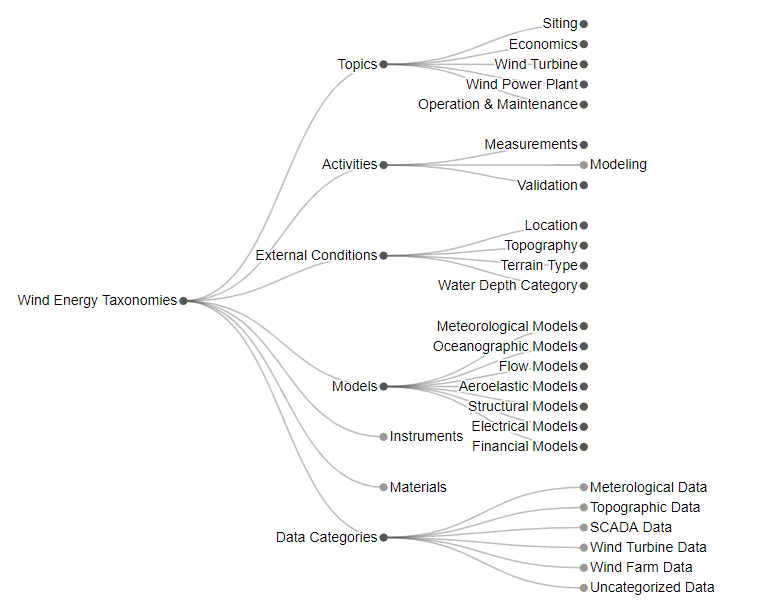
Since there was no metadata standard specific to his field, Nikola Vasiljević joined a team of researchers working on a taxonomy to describe collected data. The team based their taxonomy on the Dublin Core Metadata card, which contains 15 descriptive metadata entries. To make the taxonomy more useful within their field, they added 5 additional metadata entries: External Conditions, Activities, Instruments, Models, Materials.
A taxonomy was developed for several of the entries in the metadata card. When you catalogue your data with such metadata cards, search engines can explore the metadata cards and end-users can easily find the right dataset for their own research.
What if the existing metadata standards in your field are incomplete?
Publish and preserve
Publishing your research data and metadata online provides you with an extra location for people to find your work. Even though your publications contain your results, your data may still not be findable. Metadata are machine-readable, and when they have a persistent identifier, search engines can easily find them.
To be FAIR, your data (and metadata) must have a findable persistent identifier. The persistent identifier is typically assigned when a digital resource is placed in a data repository.
How can you make your metadata findable?
Nikola Vasiljević plans to make both the research data and metadata from the wake simulation project open to all. He intends to publish the data in his university repository with a rich descriptive metadata record to make his data FAIR.
Descriptive metadata such as title and keywords are machine-readable and can make a data set easier to find. The link to publications, references and licences will also be part of the metadata record.
Have a look at Nikola's dataset in the institutional repository, DTU Data.