





Documentation
Documentation adds context to your data and makes the data easier to understand and reuse in the future.
What is documentation?
Imagine finding a dataset you created a long time ago. Now think of the contextual information that you would need to determine whether these data are relevant to your current research and whether you would be able to understand how they were created: What data? What data type? Who created the data? When? Where? In which context? By which method? … and so on.
Now, imagine finding a dataset that another researcher has produced. It contains a large table, where all column headers contain four-letter-abbreviations. If these abbreviations are not properly documented and resolved, you will never be able to understand nor use the data correctly. So, the more documentation of the data’s original context the better.
Difference between documentation and metadata
Two general types of data documentation
We distinguish two general types of data documentation that must be included with your data to make them FAIR: data-level documentation and project-level (or: study-level) documentation.
Data-level documentation
Data-level documentation includes information about specific data files like:
• Data type
• Structure of the data, e.g. questions, variables, concepts
• Data processing procedures, … and so on (this list is not exhaustive)
Project-level documentation
Project- or study-level documentation describes:
• When, how and why the data were generated and by whom
• How the data were processed
• What quality assurance measures have been used, … and so on (this list is not exhaustive)
Learn more
For your project, specific documentation requirements may apply. To learn more, take our
e-Learning module 3 on data management plans.
Example of data-level documentation
Within Carsten Brink’s research area, the researchers have collected patient data and now they document how they map the clinical data to a new structure following a standard ontology. This mapping step is necessary for distributed learning (their preferred method to provide access to sensitive data), but very time consuming.
To ensure that their data can be understood by others, a data map like this one is included in their data-level documentation:
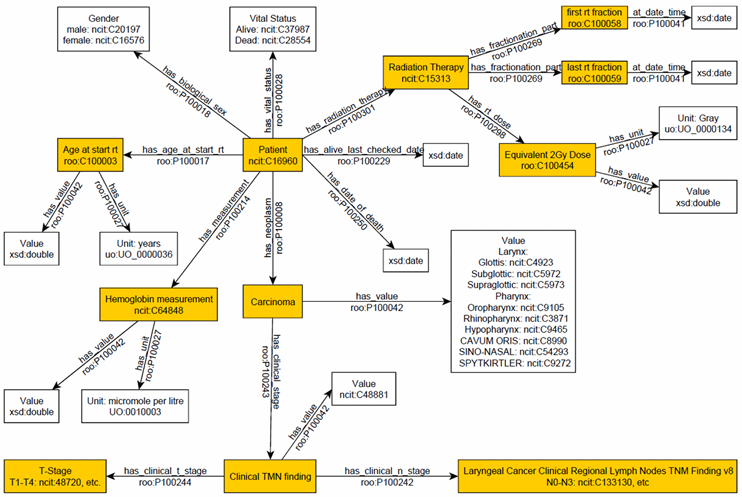
When the researchers have finished their analyses, they document their methods.
For small projects the entire code is stored, while for larger projects the researchers prefer to describe the method, the model selection and the packages used.
Examples of project-level documentation
Example 1: Wind Energy
Example 2: ISSP
Data management planning
Planning how to FAIRify your data in the early stages of your research project will help you save time and resources later on. In practice, this means writing a data management plan, or DMP. A DMP is also where you document how you will collect, store, process, share and dispose of your data. Planning the management and FAIRification of your data minimises the risk of problems at a later stage - be these technical, legal, or practical.
Remember that making your data FAIR is a gradual process with small steps one at a time. So, think about how your data will be created, collected, documented, stored, shared, archived, and preserved - and how you can make them FAIR at each step.
Planning your data documentation lays the foundation for the rest of your research project. Imagine you would like to use another researcher’s dataset. If clear documentation is not provided, the data are not FAIR - and you will not be able to interpret the data. Depending on the type of research you conduct, you would document different elements of your research process, for instance your data collection methods, the code book, trial protocols, your device settings, or your laboratory procedures. For your specific project, other documentation requirements may apply.
To learn more, take our e-Learning module 3 on data management plans and have a look at the additional resources on the links page.
While you work
While actively working on your research project, you collect and create, process, analyse, and interpret data. To ensure that your data are FAIR, you record the context of all research decisions, continuously update your field or laboratory notebook, and keep track of all changes to your data.
Example 1: Wind Energy
Example 2: ISSP
Publish and preserve
Documentation comes in many forms. When you are preparing your research data for publication or preservation, you should link any necessary documentation with your data.
FAIR documentation is what enables you as a researcher to show how the data was generated and for what purpose. Think about what information is necessary for this to happen:
- Methodology descriptions
- Codebooks
- Questionnaires
- Scripts like editor- and do-files (STATA)
- Laboratory notebooks and experimental protocols
- Software syntax and output files
- Database schemes
- Provenance information about secondary data
- The finalised data management plan
Some of this information may already be explained in your publications. However, publishing the documentation together with your data in a repository will boost the reusability of your data and the likelihood of your data being cited.