





File formats
File formats determine how data can be used. It is important to decide what file formats to use for data collection, data processing, data archiving, and long-term preservation.
File formats
Files are saved in different formats. File formats are standard ways to store data on a computer and define how bits are used to encode information in a digital storage medium. Files are usually named like this: [prefix].[suffix] or filename.type. The prefix is a name which is used to identify the file, and the suffix indicates the file type. In this way files of the type .txt are text encoded files and usually contain text and/or numbers. Images are often saved in .jpg or .bmp while audio can be saved in the .mp3 or .wav file format.
Some file formats are proprietary – like .nef or .wma which are owned by Nikon and Microsoft. Other file formats like .txt or .csv are non-proprietary and can be used with a variety of software. Different file formats have different characteristics and properties and thus determine how data can be used. The purpose of a file should help determine which file format to choose. Therefore, you may have to keep some data files in multiple formats. It is important to plan what file formats to use for each purpose: data collection/ processing/analysis, reuse, and preservation.
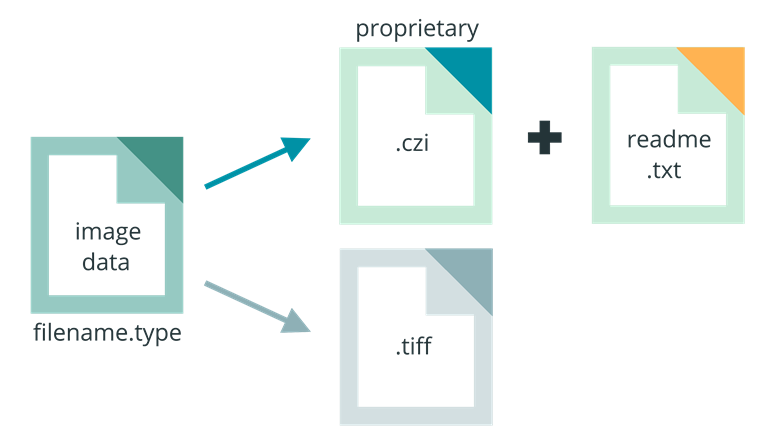
When it is necessary to save files in a proprietary format, consider including a readme.txt file in your directory that documents the name and version of the software used to generate the file, as well as the company that made the software. This could help you down the road, if you need to figure out how to open these files again.
While you work
Make sure that the file formats you choose can hold the necessary data elements and information you need. Here are a few examples:
Example 1
Example 2
The researchers in the ISSP use both STATA and SPSS in order to accommodate that data users can use their preferred statistical software.
Both are proprietary formats for statistical data, but the formats can retain a lot of the information in the data like the values and variable names as well as variable and value descriptions (labels) that cannot be stored in CSV.
Conversions between the two formats are easily done as each software solution supports saving in other formats. To make sure that no information is lost in file conversions, a copy of the original dataset is kept unaltered.
STATA (click to enlarge)
SPSS (click to enlarge)
Example 3
Publish and preserve
You have to consider whether the file formats used for data collection, processing, and analysis are also appropriate formats for long-term preservation.
Choosing the right file format for publishing and preserving research data determines how or even if you or others can access and use the data later.
Here are some examples of preferred FAIR file formats for preservation:
Containers: TAR, GZIP, ZIP
Databases: XML, CSV, JSON
Geospatial: SHP, DBF, GeoTIFF, NetCDF
Video: MPEG, AVI, MXF, MKV
Sounds: WAVE, AIFF, MP3, MXF, FLAC
Statistics: DTA, POR, SAS, SAV
Images: TIFF, JPEG 2000, PDF, PNG, GIF, BMP, SVG
Tabular data: CSV, TXT
Text: XML, PDF/A, HTML, JSON, TXT, RTF
Web archive: WARC
Not the format you were looking for? See this Wikipedia page on different file formats.
Example 4
What are other considerations?
When choosing file formats to publish or preserve your data, try to keep the following considerations in mind:

Choose formats common to your field
To ensure the interoperability and reusability of your data, it is vital to preserve the data in a format common to your field.
For example, as long as Carsten Brink is working with the images and the patients, he would not convert his DICOM images to TIFF, because the TIFF-format cannot contain all the metadata that are captured in the DICOM format (patient data, place of tumour, duration and dose of radiation etc.). But if the purpose later on is to preserve the images themselves, then TIFF would be an appropriate format. Any relevant metadata could be saved in another file in TXT format.
This is the so-called sidecar approach.

How long do you intend to preserve your data?
Time is a critical factor for the right choice of preservation formats.
The longer the time span for the future use of the data, the more you will have to use open, standardised and well documented file formats in order to avoid obsolescence.
At the same time, you must consider the storage media for your data – where to store your data? For more information, have a look at the Access to data page.

File conversion can lead to data loss
To avoid loss of information in file conversion, it is important to use a common, multi-platform file format that follows specific standards, as you work on the data across different platforms and software solutions.
If conversion to an open data format could result in some data loss from your files, you might consider saving the data in both the proprietary format and an open format. Also there might be errors in the conversion software that is used, so it is a good idea to check the data before and after.
For example: If you need to keep the history of changes in a document written in MS Word, you should not keep the file in pdf only, but in both formats, to ensure optimal usability and preservation of data and metadata. This might not always be possible due to storage space constraints but is worth considering.
Check data repository requirements
Many journals, archives and data repositories require that data are uploaded in certain file formats.
This is important to plan for already in the beginning of your project, so you can choose the best file format for collection, processing and ultimately sharing with conversion between the different phases of your research in mind.
If you are using the Danish National Archives for preserving your research data, be aware that they require certain formats. See more here.
See FAIRsharing.org. Here Standards are linked to repositories.
Want to learn more?
Check out the CESSDA training on file formats and data conversion for more recommendations on file formats for operability, file formats for the future, data conversion and possible data loss, and planning ahead for data publication.
Also check FAIRsharing.org for data conversion and metadata standards