




Persistent identifiers
To make your data easy to find and accessible, you must provide your data and metadata with a persistent identifier. A persistent identifier is a long-lasting reference to a digital resource and provides the information required to reliably identify, verify and locate your research data.
What is a persistent identifier?
A persistent identifier (PID) is a long-lasting reference to a digital resource and provides the information required to reliably identify, verify and locate your research data eliminating many misunderstandings. A PID may also be connected to a set of metadata which describes a digital resource.
Notable persistent identifiers are the Digital Object Identifier (DOI) and the Handle System which can both be assigned to data to identify them uniquely. The DOI system uses the Handle System, which is the best infrastructure component available today for managing digital objects. While DOIs are mainly assigned to resources ready for public dissemination, Handles are in general used to persistently identify other categories of digital resources (e.g. those created in the labs) to make them referable by software, workflows etc.
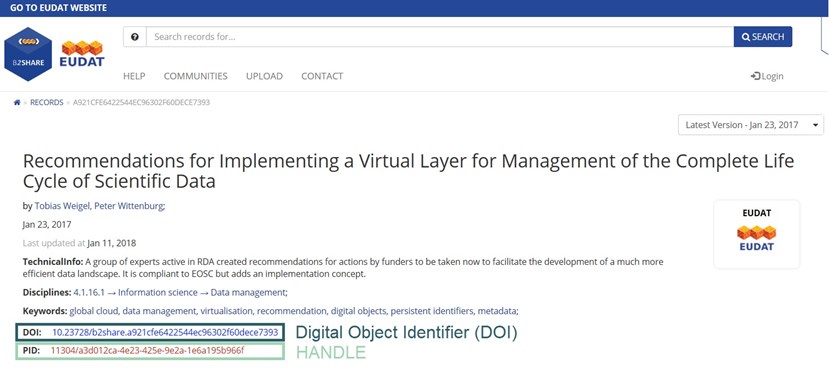
Example 1
This is what a DOI and a Handle look like at the EUDAT Collaborative Data Infrastructure, one of the largest infrastructures of integrated data services and resources supporting research in Europe.
How to get a PID
To make your data accessible and easy to find, you must provide your data and/or your metadata with a PID. This can be done by making a record in a trusted or recommended repository.
Find a repository that will provide a PID for your research data by:
- Browsing through the list of repositories recommended by the European Research Council.
- Visiting re3data.org, which is a global registry of research data repositories from different academic disciplines.
- Exploring FAIRsharing, which allows you to discover databases grouped by domain, species or organization.
- Checking whether your institution has a local repository that can provide a PID. Many institutions are now able to provide PIDs for research data stored at their own local repository.
- For Danish research data, you can submit your research data to the Danish National Archives, although not all data types are accepted.
- Or check our recommended data repositories listed here.
Before assigning a PID, it is important to consider who has the responsibility and the rights for registering the PID and, later on, making updates if needed.
No PID? Not FAIR!
If your data and/or metadata are only stored internally at your institution or at another repository that does not issue a PID, they will not be FAIR.
Example 2
Which data need a PID?

Ensure reproducibility
To ensure reproducibility of your research data, assign persistent identifiers to your processed data.

Ensure reuse
To ensure your research data can be reused you can assign persistent identifiers to the raw data, and not as the last task before they get archived but immediately after data collection!